
Table of Contents
In the domain of machine learning, the effectiveness of a model heavily depends not only on the architecture and algorithm but also on the hyperparameters chosen.
Hyperparameters are the settings that govern the learning process and model architecture, they are not learned from the data but rather set before the learning process begins.
Properly tuning these hyperparameters can significantly enhance a model’s performance, leading to better accuracy and faster convergence. This process of finding the optimal hyperparameters is called hyperparameter optimization (HPO), and it plays a crucial role in maximizing the potential of machine learning models.
Understanding Hyperparameters
Let’s imagine a car engine. Now, when you think about making the car run its best, there are a few important things to consider. There’s engine oil, spark plug gap, tire pressure. All these settings are really important for making sure the car runs its best, but they’re not things the car learns or figures out on its own. Instead, they’re all set by you before the car even starts moving. It’s a bit like having a recipe for the perfect cake , you need to get all the ingredients and measurements just right before you start baking.
In the world of machine learning, we call these settings ‘hyperparameters.’ They’re like the special settings we provide the model before it starts learning how to do something. Just like with the car engine, getting these hyperparameters right is super important for making sure the model learns and performs at its best. On the other hand, parameters are the variables that the model learns from the training data, such as weights and biases in neural networks.
Important Hyperparameters
In machine learning, some key hyperparameters that often have a significant impact on the performance of machine learning models include:
- Learning Rate: Imagine you’re trying to teach a robot to walk. The learning rate is like how big of a step you want the robot to take each time it tries to improve its walking. In machine learning, the learning rate is a hyperparameter that controls the size of the steps taken during the optimization process, such as gradient descent, in order to minimize the loss function. It determines the rate at which the model weights are updated during training. A high rate can lead to overshooting the optimal solution, while a low rate makes training very slow.
- Number of Hidden Layers and Units: In a neural network, you have input layers, hidden layers, and output layers. The hidden layers are the layers between the input and output layers where the network learns patterns from the input data. The number of hidden layers refers to how many of these layers are present in the network. If the network doesn’t have enough capacity it may struggle to capture the complexity of the underlying patterns. This can result in underfitting, where the model performs poorly both on the training data and unseen data. Having too many hidden layers or units can lead to overfitting. Overfitting occurs when the model learns to memorize the training data rather than generalize from it. In this case, the model may perform very well on the training data but poorly on unseen data.
- Activation Functions: Activation functions such as sigmoid, tanh, or ReLU are mathematical functions that determine the output of a neuron in a neural network. They introduce non-linearity to the network, which produces outputs that are not directly proportional to their inputs, allowing neural networks to learn and represent more complex relationships in the data.
- Batch Size: The number of training examples processed in each iteration during training, which affects the stability of the training process and the convergence speed. If the batch size is too high, it can improve computational efficiency but might lead to slower convergence and poorer generalization, whereas if it’s too low, it may enhance generalization but potentially at the cost of slower training and increased memory usage.
- Regularization Parameters: Imagine you’re learning to ride a bike. Regularization is like having someone gently guiding you to stay on the right path and avoid falling off. If the guidance is too strong, you might not learn much because it’s too restrictive. But if it’s too weak, you might wander off too much and not learn the right things. Regularization parameters are hyperparameters used in machine learning algorithms, particularly in models that aim to minimize overfitting by penalizing overly complex models. Regularization helps prevent models from fitting the noise in the training data and encourages them to learn generalizable patterns instead. Common regularization techniques include L1 regularization (Lasso), L2 regularization (Ridge), and dropout.
- Optimizer: In machine learning, an optimizer is a crucial component of the training process for models, especially in neural networks. Its main function is to adjust the model’s parameters (such as weights and biases) iteratively during training to minimize the error or loss function and improve the model’s performance on the training data. There are various optimization algorithms available, each with its own advantages and characteristics. Some common optimizers include Stochastic Gradient Descent (SGD), Adam, RMSprop, and AdaGrad.
- Kernel Size and Stride: These terms are often used for image recognition and other tasks involving grid-like data, specific to convolutional neural networks (CNNs). The kernel (also known as filter) is a small matrix that slides over the input data and compute. The stride is a parameter that determines the step size of the kernel as it moves across the input data during convolution. Adjusting these parameters can influence the network’s ability to capture different levels of detail in the input data.
- Pooling Operations: Pooling operations are like looking at a picture and picking out the most important parts. Pooling operations in CNNs help to reduce the spatial dimensions of feature maps while preserving important information, making the representations more manageable, less sensitive to small changes, for example, max pooling or average pooling, which help capture invariant features and reduce computational complexity.
- Number of Trees and Tree Depth: The “number of trees” and “tree depth” are important hyperparameters in decision tree-based methods like Random Forest and GBM. Finding the right balance between the number of trees and the depth of each tree is crucial for building accurate and well-generalized models. Increasing the number of trees can improve performance up to a point, while controlling the tree depth helps prevent overfitting. Increasing the tree depth allows the model to capture more complex patterns in the data, potentially leading to better performance on the training data. However, deeper trees are more prone to overfitting.
Challenges in Hyperparameter Optimization:
Hyperparameter optimization is a complex and challenging task due to several reasons:
- Search Space Dimensionality: Hyperparameter optimization typically involves exploring a large and multidimensional search space. Each hyperparameter can take on a range of values or discrete options, leading to a combinatorial explosion of possible configurations.
- Computational Cost: Evaluating the performance of each hyperparameter configuration requires training and validating the model, which can be computationally expensive, especially for deep learning models. Iteratively searching through the hyperparameter space can consume significant computational resources and time.
- Interdependencies: Hyperparameters are often interdependent, meaning that changing one hyperparameter may affect the performance of others. Finding the right combination of hyperparameters requires considering these interdependencies, which adds complexity to the optimization process.
Techniques for Hyperparameter Optimization:
Several techniques have been developed to tackle the challenges of hyperparameter optimization:
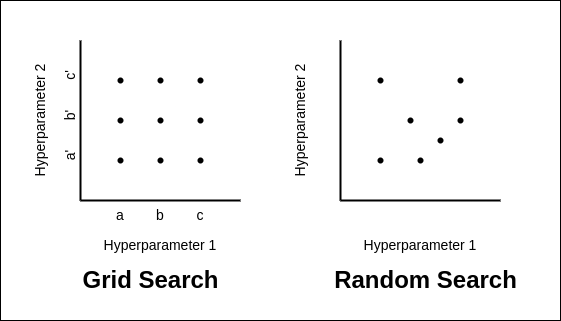
- Grid Search: Grid search works like this: You have a grid, like a table, where each row represents a different combination of hyperparameters. You try out all the possible combinations by running the model with each set of hyperparameters. Then, you see which combination gives you the best performance on your data. Grid search is a simple and straightforward approach that exhaustively searches through a predefined grid of hyperparameter values. While easy to implement, grid search is computationally expensive and becomes impractical for high-dimensional search spaces.
- Random Search: Instead of trying out every possible combination like in grid search, random search randomly selects combinations to try. It’s like grabbing random ingredients from your pantry to experiment with in your recipe. Despite its simplicity, random search often outperforms grid search, especially in high-dimensional spaces, by efficiently exploring the search space.
- Bayesian Optimization: It’s like you’re trying to find the peak of a mountain, but you can’t see the whole landscape. Bayesian Optimization is like having a guide who gives you suggestions on where to look next based on the information you’ve gathered so far. Bayesian optimization employs probabilistic models to model the objective function and iteratively explore the hyperparameter space. By using past evaluations, Bayesian optimization focuses the search on promising regions, making it computationally efficient. Bayesian optimization is indeed more complex than grid or random search, but its efficiency lies in its ability to use probabilistic models to navigate the hyperparameter space. Despite potentially requiring more computational resources, it excels at finding optimal configurations for larger and more complex models.
- Evolutionary Algorithms: Imagine training a machine learning model is like raising a champion race car driver. Evolutionary algorithms in HPO are like a breeding program. They start with different settings (like gear ratios and tire pressures), test them on a track (performance metric), and pick the best ones to create even better racers (models) in the next generation. This continues until you find the winning setup (best hyperparameters). AutoML is one of the example of these algorithms.
Best Practices for Hyperparameter Optimization
To effectively optimize hyperparameters and maximize model performance, consider the following best practices:
- Understand the Problem Domain: Gaining insights into the problem domain, dataset characteristics, and the behavior of various algorithms and architectures is essential. By leveraging domain-specific knowledge, use hyperparameter optimization strategies accordingly. This approach ensures that optimization efforts are aligned with the unique requirements of the problem.
- Use Cross-Validation: Cross-validation is a technique used in hyperparameter optimization to assess the performance of a machine learning model. It involves partitioning the dataset into multiple subsets, called folds. The model is then trained on a subset of folds (the training set) using different hyperparameter configurations and evaluated on the remaining folds (the validation set). This process is repeated multiple times, with different combinations of training and validation sets, to ensure robust evaluation. The goal is to select hyperparameters that result in a model with good generalization performance, meaning it performs well on unseen data.
- Parallelized Computation: This involves utilizing distributed computing frameworks and cloud-based services to run multiple experiments concurrently, thereby reducing the time required for experimentation. Distributed computing frameworks such as Ray allow for parallel execution of tasks across multiple nodes or processors. By distributing the workload efficiently, these frameworks can speed up the hyperparameter optimization process by running multiple model training and evaluation tasks simultaneously.
- Monitor and Analyze Results: Continuous monitoring of various hyperparameter configurations throughout the optimization process is crucial. By analyzing performance trends, visualizing results, and drawing insights, it becomes possible to guide further experimentatio effectively.
Tools for Hyperparameter Optimisation
- Optuna: Optuna is an automatic hyperparameter optimization framework that offers various optimization algorithms and is highly customizable, making it suitable for a wide range of machine learning tasks.
- Hyperopt: Hyperopt is a Python library for optimizing machine learning models using Bayesian optimization. It supports various optimization algorithms and integrates well with popular machine learning frameworks like scikit-learn.
- scikit-learn: scikit-learn provides utilities for hyperparameter tuning such as GridSearchCV and RandomizedSearchCV, offering simple yet effective methods for tuning hyperparameters in scikit-learn models.
- TensorFlow Model Optimization Toolkit: TensorFlow Model Optimization Toolkit offers techniques for optimizing neural networks, including hyperparameter tuning using tools like tf.keras.tuner and tfp.experimental.distribute, providing efficient optimization for TensorFlow models.
- Keras Tuner: Keras Tuner is an easy-to-use hyperparameter optimization library for Keras models. It includes hyperparameter search algorithms like RandomSearch and Hyperband, simplifying the process of finding optimal hyperparameters for Keras models.
- Ray Tune: Ray Tune is a scalable hyperparameter optimization library that supports various machine learning frameworks such as TensorFlow, PyTorch, and XGBoost. It provides functionalities for distributed hyperparameter tuning, making it suitable for large-scale optimization tasks.
- Katib: Katib is an open-source hyperparameter tuning framework within the Kubernetes ecosystem, designed for Kubernetes-native machine learning workflows. It offers scalability, integration with Kubeflow, and support for various optimization algorithms, making it ideal for optimizing models deployed on Kubernetes clusters.
Conclusion
Hyperparameter optimization is a critical aspect of building successful machine learning models. By carefully tuning hyperparameters, one can unlock the full potential of their models, achieving higher accuracy, faster convergence, and better generalization. While hyperparameter optimization poses challenges such as high-dimensional search spaces and computational costs, various techniques and best practices can help navigate these challenges effectively.